- Microsoft’s official GDC 2026 announcement summary covering the DirectX tooling updates
- introduces DirectX Dump Files (.dxdmp) that capture hardware state, driver/OS state, and custom game data on GPU crash
- also announces Shader Explorer in PIX for offline cross-GPU static shader analysis, GPU hardware counters in PIX System Monitor, a new GPU capture file format, and the future goal of live on hardware shader debugging

- AMD’s overview of their GDC 2026 collaboration with Microsoft
- details AMD’s support for the new DirectX ML features: DX Linear Algebra accessing WMMA cores on RDNA hardware directly from HLSL, and the DirectX Compute Graph Compiler (CGC)
- lists hardware support for the newly released features
- author summaries and comments on Microsoft’s D3D12 announcements from GDC 2026
- covers five areas: GPU debugging tools, ML advancements, Advanced Shader Delivery, DirectStorage 1.4, and DXR 2.0
- Keith Stockdale shares his experience at the first Shading Languages Symposium
- recurring topics across talks included: shader debugging pain points and the lack of printf in HLSL, testing frameworks for shader code, shareable/modular shader libraries
- notable discussions included whether shading languages should converge with C++

- NVIDIA GTC is starting March 16 attend virtually for free.
- Presenting the latest breakthroughs in generative AI, accelerated computing, simulation technology, and more.
- My top sessions: OpenUSD Crash Course (DLIW82272), Fundamentals of GPU-Accelerated Workflows (DLIW82265) and more
- Win an RTX Pro 6000 GPU and see my full session recommendations here

- Brian Karis details how Reyes-style displacement mapping tessellation was integrated into Nanite
- explains the new pipeline stages and how they fit into the existing structure
- discusses key implementation challenges, including bounding displaced patches for culling, computing texture UV derivatives, and vectorizing scalar-heavy per-patch work across multiple patches per wave
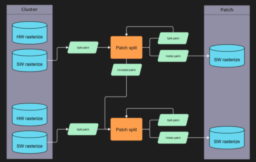
- discusses the problem of efficiently handling variable-sized work
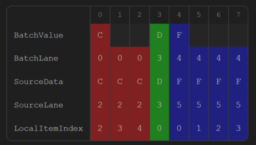
- introduces a wave-local work distribution technique where the producer data stays in registers and consumers use WaveReadLaneAt to read it, avoiding costly round-trips to global memory queues
- applies this primitive in three places within the tessellation pipeline
- Presents a well-commented HLSL implementation of participating media concepts from Physically Based Rendering (PBRT 4ed), covering homogeneous and heterogeneous volumes with absorption, scattering, and emission using delta/null tracking
- shares render results showing volumetric clouds, colored cubes, and emissive volumes
- documents practical implementation pitfalls
- presents a recursive divide-and-conquer algorithm for rendering SDFs on CPU that advances all rays in a view frustum quad simultaneously, recursively subdividing into four quads only when the shared march step becomes too small
- extends the algorithm with a patch-level bilinear interpolation shading mode
- demonstrates 3–4x fewer samples per pixel versus standard raymarching
- Mike Turitzin discusses his journey back into graphics programming and the motivation behind building an SDF-based game engine
- explains how the engine uses signed distance fields with sphere tracing for rendering and WebGPU as the graphics API
- shares programming philosophies around minimalism, investing deeply in chosen tools, and keeping game development the primary focus rather than falling into the engine-development trap

- presents a technique for perspective-stable 3D pixel art by rendering scene geometry into a cubemap from a grid-snapped fixed probe origin, then splatting each visible cubemap texel to screen as a world-space quad
- cubemap indexing provides rotation invariance, while snapping the probe origin to a world grid provides translation invariance

- Adobe open-sources their production OpenPBR 1.0 BSDF implementation extracted from their Eclair renderer under Apache 2.0
- single header design targeting C++, GLSL, CUDA, MSL, and Slang via a thin macro interop layer
- LUTs support two modes: self-contained constant arrays (default, no texture bindings needed) or GPU texture sampling (smaller shader binary, hardware filtering)

- dependency-free C11 library covering 13 curve families (Bezier, Hermite, Catmull-Rom, B-Spline, NURBS, clothoid, subdivision, and more) and 5 surface types (Bezier patch, B-Spline, NURBS, swept, ruled) with a uniform create/evaluate/sample/traverse/inspect API
- evaluation kernels are header-only and compile unchanged across four backends (C, HLSL, GLSL, and Halide)
- The article presents a fast approximation to asin
- follow-up to a previous article on the same topic
- benchmarks across Intel i7, AMD Ryzen 9, and Apple M4 to show the effects of micro optimizations

Thanks to Aras Pranckevičius for support of this series.
Would you like to see your name here too? Become a Patreon of this series.
